transformer 基础
概要:简要记录 Encoder-Decoder 架构、seq2seq 模型、Attention 机制
Encoder & Decoder
encoder 接收输入,生成一个固定长度的上下文向量(编码器生成的最终隐藏状态);decoder 接收上下文向量(或状态)+输入,获得输出。
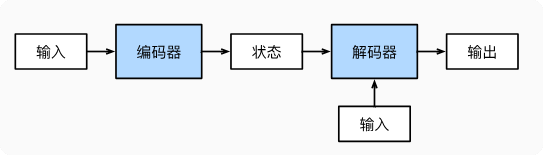
缺点:上下文长度固定,导致丢失信息。
代码实现
form torch import nn
class Encoder(nn.Module):
"""编码器接口"""
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, x, *args):
raise NotImplementedError
class Decoder(nn.Module):
"""解码器接口"""
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def forward(self, x, *args):
raise NotImplementedError
class EncoderDecoder(nn.Module):
"""编码器-解码器接口"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)
seq2seq
seq2seq 是一种使用 encoder-decoder 框架解决可变长度序列生成序列问题的模型。
在 seq2seq 模型提出前,解决序列生成序列问题,只能输入和输出均为固定长度的序列。如果输入和输出序列的长度不足,那么需要 padding + mask 来处理。
问题:
- seq2seq 模型提出前,输入输出序列要求为固定长度,意思是需要预处理输入序列长度为已定义的固定长度吗?
- seq2seq 模型可以处理可变长度序列,意思是输入序列可以是任意长度吗?如果 decoder 或 encoder 每个时间步只能处理序列中的一个单词,那么总时间步的步数需要预先定义吗?
- 为什么 seq2seq 存在短期记忆限制?seq2seq 里面的 rnn 模块只处理序列中的当前元素信息吗?也会有上一时间步的隐藏状态信息吧?但是没有更长时间前的信息了
- encoder 会输出一个最终隐藏状态,decoder 中每个 rnn 模块接收的隐藏状态都一样吗?还是说 decoder 中的每个 rnn 模块会在上一个的基础上增加一些信息?
训练和推理
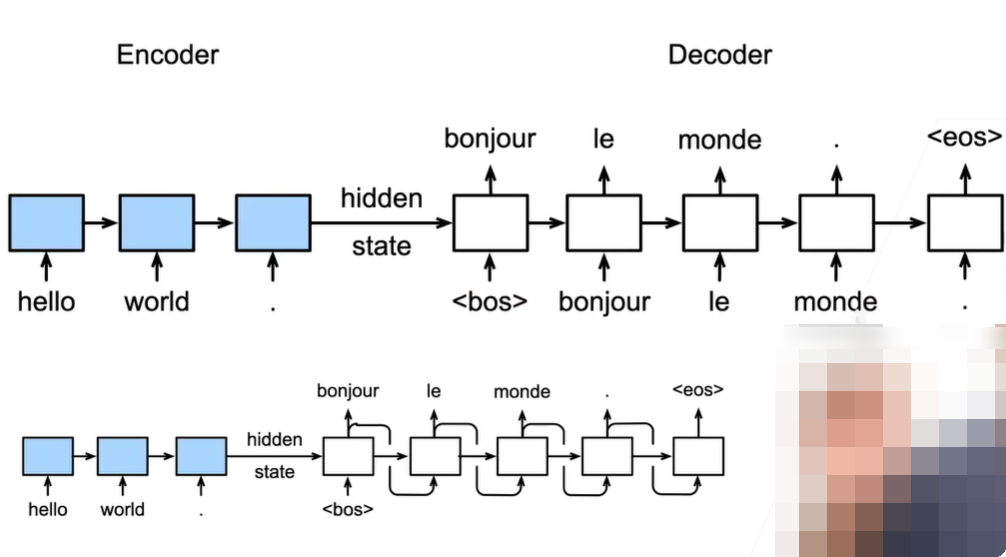
训练过程:在 decoder 中,每个时间步都输入正确的单词
推理过程:在 decoder 中,每个时间步的输入使用上一时间步的预测输出
Attention 机制
不再要求 encoder 基于整个序列编码出一个固定长度的上下文向量,而是编码出一个上下文向量序列,解决信息丢失和短期记忆限制的问题。
参考:
动手学深度学习-李沐-9.7. 序列到序列学习(seq2seq)